
Web scraping can be used to collect a wide range of data, including product information, customer reviews, pricing data, competitor data, job postings, and more. The process of web scraping involves extracting data from websites by using software tools called web scrapers or bots.
Web scrapers work by sending HTTP requests to a website's server and analyzing the HTML content of the website's pages. The software tool then extracts the relevant data by locating specific HTML tags and attributes that contain the desired information. This process is repeated for each page of the website, and the extracted data is then saved in a structured format such as a CSV or JSON file.
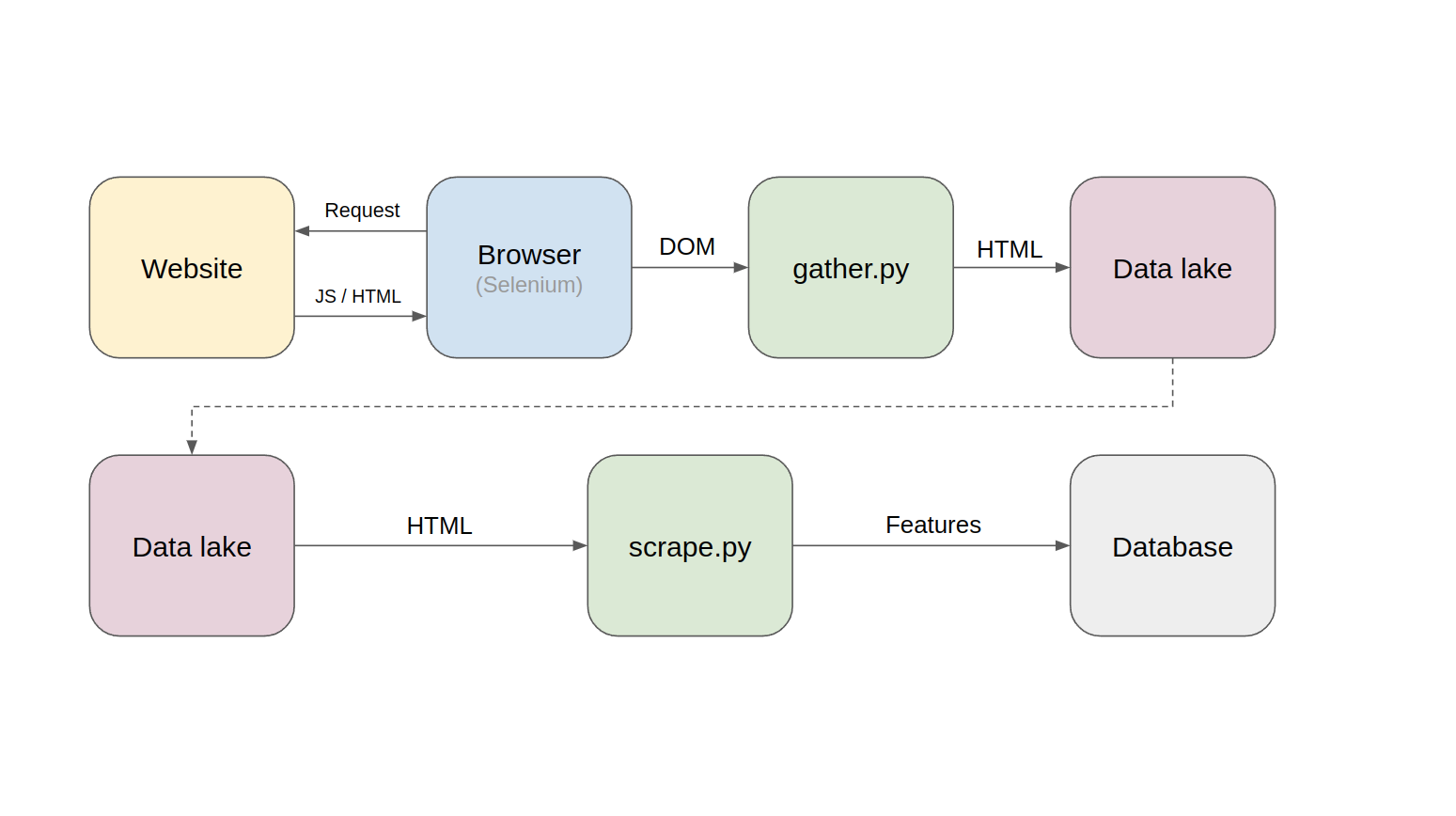
The architecture of a web scraping system consists of several components that work together to extract data from websites. The components of a typical web scraping system include:
- Web Scraping Tool: This is the software that is used to automate the process of extracting data from websites. There are several web scraping tools available, both free and commercial, such as Beautiful Soup, Scrapy, Selenium, and more
- Web Server: The web server is the computer that hosts the website from
which data is to be scraped. The web server is responsible for
responding to requests from the web scraping tool and delivering the
website's content.
- HTTP Client: The HTTP client is a program
that sends HTTP requests to the web server to fetch the website's
content. The web scraping tool acts as the HTTP client in the web
scraping system.
- HTML Parser: Once the web scraping tool
receives the website's content, it needs to parse the HTML code to
extract the relevant data. The HTML parser is responsible for parsing
the HTML code and extracting the data elements based on the web scraping
tool's configuration.
- Data Storage: The extracted data is
then stored in a database or file for further processing. The data
storage component of a web scraping system can be a relational database,
NoSQL database, or file format such as CSV or JSON.
- User Interface: The user interface is the front-end component of a web scraping system that allows users to configure the web scraping tool, specify the target website, and view the extracted data. The user interface can be a command-line interface, a web-based interface, or a graphical user interface (GUI).
Web scraping can be a powerful tool for businesses looking to gain a competitive advantage in their industry. By gathering data on competitors' prices, product offerings, and marketing strategies, businesses can make informed decisions about their own strategies and pricing.
Web scraping can also be used for research purposes, such as analyzing public opinion on a particular topic by scraping social media websites for user-generated content. Researchers can also use web scraping to gather data for academic papers, market research reports, and other types of research.
However, it's important to note that web scraping must be conducted ethically and legally. Some websites have terms of service that prohibit web scraping, and scraping data from these sites can result in legal action. Additionally, web scraping can be a resource-intensive process that can cause strain on a website's server. As a result, some websites have implemented measures to prevent web scraping, such as CAPTCHA tests or rate limiting.
Despite these challenges, web scraping remains a valuable tool for businesses, researchers, and individuals looking to gather data quickly and efficiently. As the amount of data available on the internet continues to grow, web scraping will only become more important for making informed decisions and gaining a competitive advantage.
In summary, the architecture of a web scraping system involves several components that work together to automate the process of extracting data from websites. The web scraping tool sends HTTP requests to the web server, receives the website's content, parses the HTML code, extracts the relevant data, and stores it in a database or file. The user interface allows users to configure the web scraping tool, specify the target website, and view the extracted data.



